Docker
Docker carves up a running linux system into small containers, each of its own sealed little world, with its own programs and its own everything. All isolated from anything else.
- These containers are designed to be portable, so they can be shipped from one place to another, and Docker does the work of getting these containers to and from your systems.
- Docker also builds these containers for you, and its a social platform to help you find and share containers with others who may have build similar work that you can build on top of.
- Docker is not a virtual machine. There’s only single operating system running. That operating system is just carved up into isolated spaces.
What is a container?
- A container is a self contained sealed unit of software.
- Contains everything to run the code.
- Includes batteries and the operating system
- A container includes
- Code
- Configs
- Processes
- Networking enough to talk to other containers
- Dependencies
- OS(Just enough to run the code)
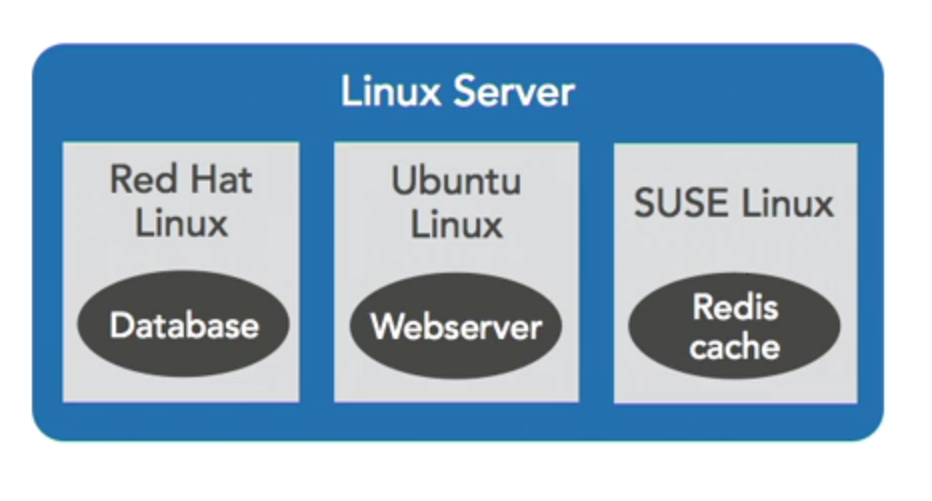
So the way it works, it takes all the services that make up a linux server : Networking, storage, code, interprocess communication, the whole works and it makes a copy in the Linux kernel for each container.
So each container has its own little world it can’t see out of and other can’t see in. You might have one container on a system running Red Hat Linux, serving a database, through a virtual network to another container running Ubuntu Linux running a web server that talks to the database, and that web server might also be talking to a caching server that runs in SUSE Linux based container.
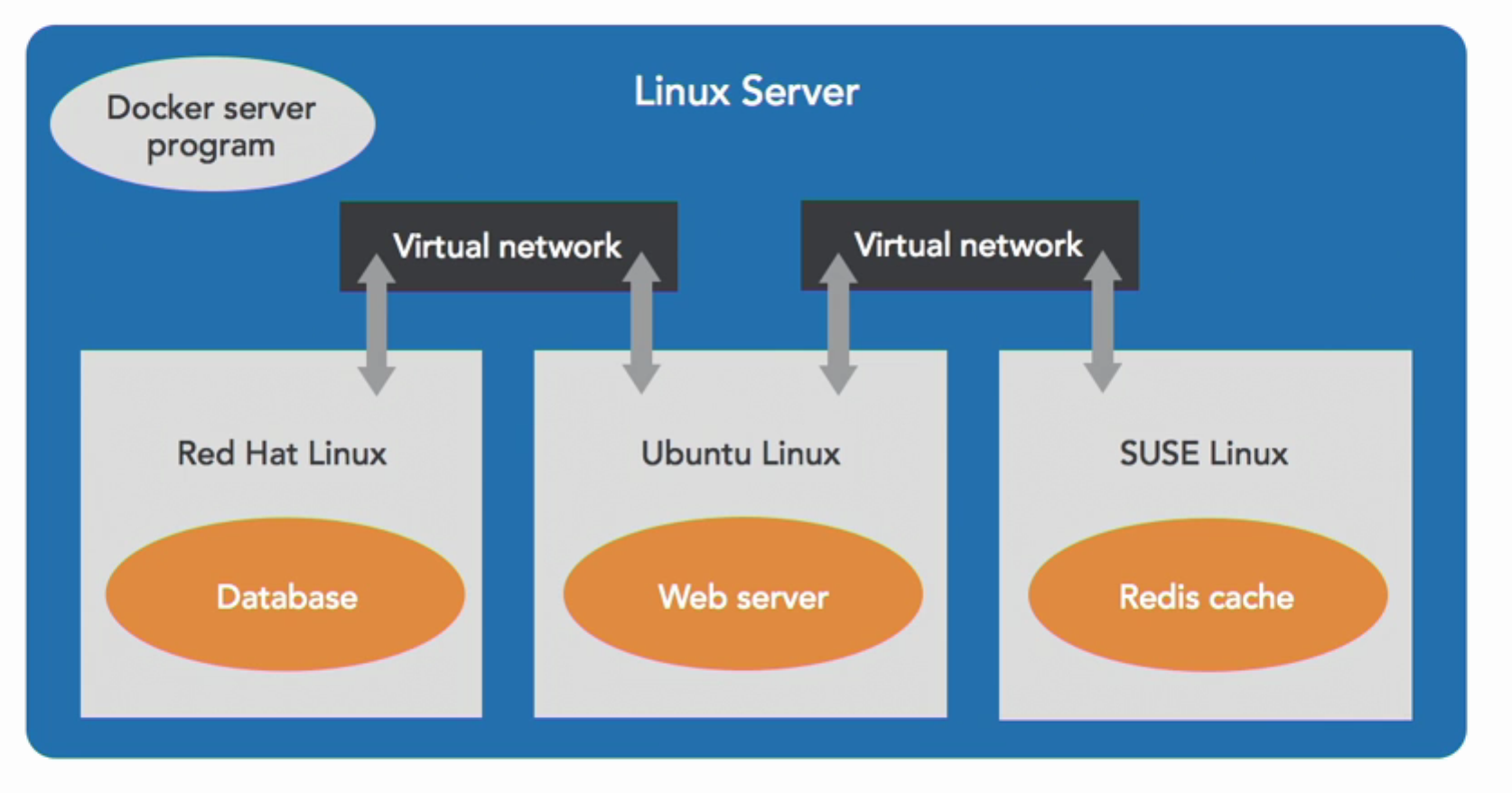
The important part to understand is it doesn’t matter which linux each container is running on, it just has to be linux.
And docker is the program that manages all of this. Sets it up, monitors it, and tears it down when it’s no longer needed.
Docker is a client program, named Docker, it’s a command you type at the terminal.
It’s also a server program that listens for messages from that command, and manages a linux running system.
Docker has a program which builds container from code. It takes your code along with its dependencies and bundles it up and then seals it into a container.
And its a service that distributes these containers across the internet and makes it so you can find others work, and right people can find your work.
Its also a company that makes all of these.
Docker Flow : Images to Containers
In Docker it all begins with an image, An image is every file that makes up just enough of the operating system to do what you need to do.
Traditionally, you’d install a whole operating system with everything for each application you do. With docker you pair it way down so that you have a little container with just enough of the operating system to do what you need to do, and you can have lots and lots of these efficiently on a computer.
To list images
docker imagesOUTPUT : REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu latest f643c72bc252 5 weeks ago 72.9MB hello-world latest bf756fb1ae65 12 months ago 13.3kBREPOSITORY: Where the image came fromTAG: Version numberIMAGE ID: Internal docker representation of this image.In any docker command i can refer to the image as
ubuntu:latesti.eREPOSITORY:TAGOR by itsIMAGE ID
To run an image
docker run -ti ubuntu:latest bashtstands for terminal,istands for interactive. The above command will open a bash shelldocker runcommand takes an image and turns it into a living container with a processTo exit an image type
exitorctrl + DTo check running images/containers
docker psOUTPUT : CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 810fba31196d ubuntu:latest "bash" 40 seconds ago Up 38 seconds lucid_noyceCONTAINER ID: Unique container id. Different fromIMAGE ID. Cannot be interchanged
Here’s the difference between docker and virtual machines or running things on a real computer. When you’re inside a container you start from an image and it doesn’t change. When i make a container from the image, i don’t change the image.
So if i make some changes in a running container let’s just say create a file named a.txt and in a new parallel terminal window i run the image again(which will make a new container) than a.txt will not be in that container.
Even if i exit the container in which i created the file and run the image again in a new terminal window than the it will start fresh and a.txt will not be in that container because that will be a fresh new container.
Docker Flow : Containers to Images
So we went from an image to a running container. When we ran that container again, we got the same thing we got the first time. And that’s the whole point of images, it’s they are fixed points where you know everything’s good and you can always start from there.
Now when you’ve got a running container, you make changes to that container, you put files there, its very useful when you want to be able to actually save those.
The next step in docker flow is a stopped container. When the process exits, the container is still there. When we create a file and exit the container, it’s still there. We can go back and find it. It didn’t get deleted. It’s just that it’s currently in a stopped container.
To see all containers
docker ps -aTo see last created container
docker ps -lAlright so let’s say we have a stopped container that has a file we want to use for the future. We have made our changes installed our software. The next step is
docker commitcommand. That takes containers and makes images out of them.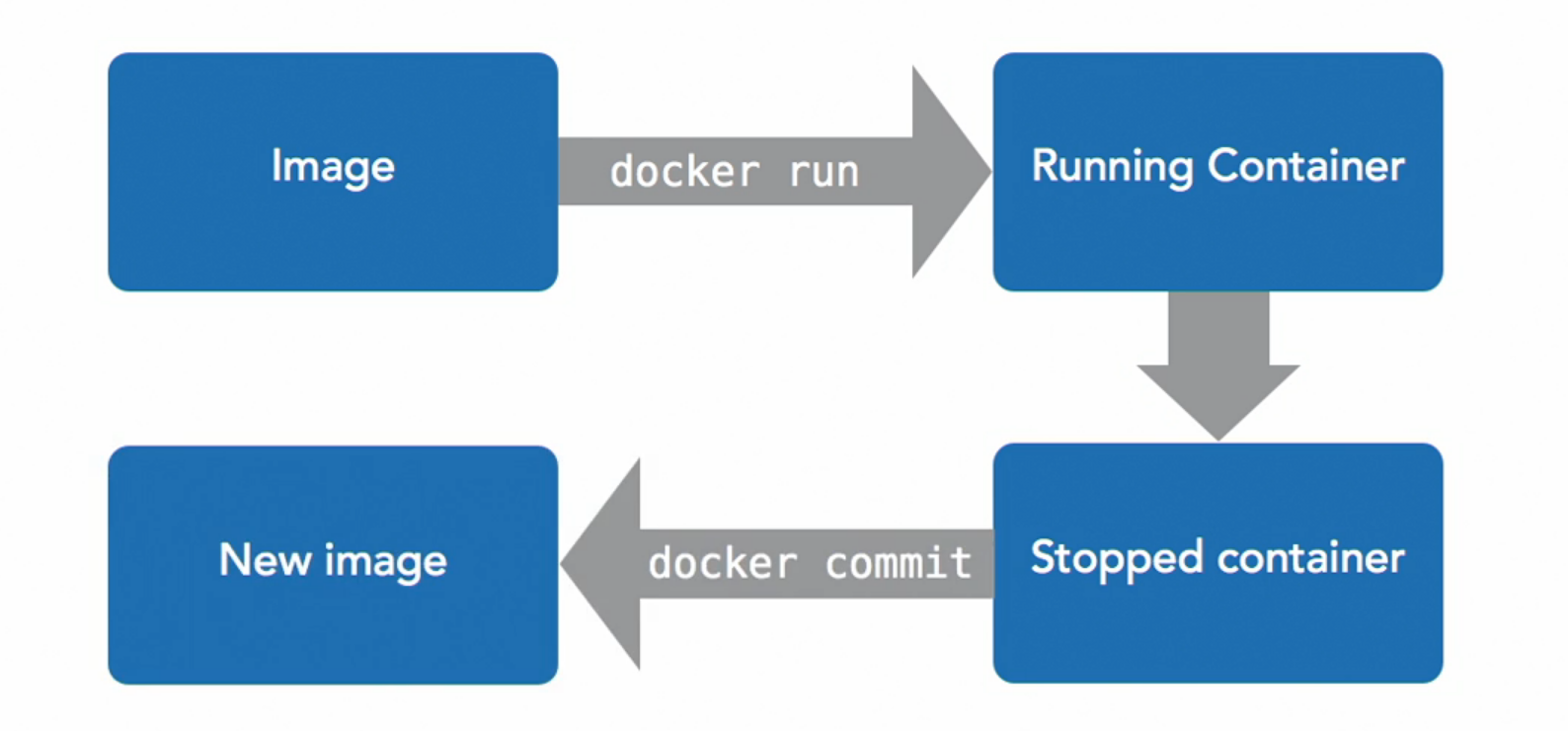
It doesn’t delete container, the container is still there. Now we have an image with the same content that was in that container. So
docker runanddocker commitare complimentary to each other.docker runtakes images and to container anddocker committakes containers back to images. It doesn’t overwrite the image that the container was made from.To commit : making image from a container
docker commit CONTAINER IDIt will return a
shaand make an image. To give name to that image you can dodocker sha image_nameAfter this you can check by running
docker imagesand you will find your image thereWe can simplify the above process by doing this. It was just to demonstrate what is going on under the hood.
docker commit CONTAINER_NAME IMAGE_NAME
Running Processes in Containers
Now that we’ve got the Docker flow in mind let’s talk about running steps in docker because that’s what it’s all about.
docker runstarts a container by giving an image name and a process to run in that container.This is the main process to a container. When that process exits, the container’s done.
If you start other processes in a container later which we’ll cover, the container still exits when that main process finishes.
So Docker containers have one main process and they can have names. If you don’t give it a name it’ll make one up.
docker run --rm -ti ubuntu sleep 5--rmmeans when you want to run something in your container but don’t wanna keep the container afterwards . This says that delete the container when it exits.docker run --rm -ti ubuntu bash -c "sleep 3; echo all done"Very often we want to start a container that says first run this. When it finishes, run the second thing. This pattern is extremely common for that. So in the above command container will first sleep for 3 seconds than will echo “all done”.
docker run -d -ti ubuntu bashOUTPUT : 039b397e383bae0be701c180ac9fc6ee37d2103f1172d94e039b6407b7b4c151Docker has this idea of detached containers. You can start a container running and just let it go. It’ll print an identifier by which you can attach to this identifier. You don’t have to use this identifier as you can use the
docker pscommand to see the name and attach the container.docker attach CONTAINER_NAMEIt’ll attach you to the container which was running in background.
To detach from the container press
Ctrl + p, Ctrl + q. It exits you out of the container by detaching from it.So say if you want to run more processes in a container because until we were only using one process in a container. We can do this by using
docker execcommand.So say in one terminal window you have your container running. Now open a new window and run
docker exec -ti CONTAINER_NAME bashIt’ll start the same container you have in your first terminal window assuming the container name is same. You can verify it by creating a file in one window and doing the
lsin other window as you’ll see it there.If you exit from one window, the other window will also exit the container.
Manage Containers
Looking at a container output of something that’s already finished can be very frustrating. You start up a container, it didn’t work, you want to find out what went wrong.
docker logscommand is the key for this. Docker keeps the output of the container available. It keeps it around as long as you keep the container around.You can use
docker logs CONTAINER_NAMEto look at what the output was. For eg.docker run --name example -d ubuntu bash -c "llll"Suppose we accidentally executed a command which is wrong and it won’t work. Later when we see its not running we can check what went wrong by running
docker logs exampleOUTPUT : bash: llll: command not foundYou can view the logs of a container as many times you want as long as it is there.
Don’t let the output of your docker containers get really really huge. It’s very convenient, being able to go back and look at it. And if you’re writing tons and tons of data to the output of the process in your docker container, you can really bog down docker to the point where your whole system becomes unresponsive.
Stopping and Removing Containers
- You can
killa running container. And when you’ve killed it, it goes to the stop state. And when you’re done with a container in the stopped state, you remove it. docker kill CONTAINER_NAMEmakes it stop.docker rm CONTAINER_NAMEmakes it gone.- Stopped containers still exist until you remove them.
Resource Constraints
One of the big features of docker is the ability to enforce on how many resources a container is going to use.
You can limit it to a fixed amount of memory.
docker run --memory maximum-allowed-memory IMAGE_NAME commandYou can equally limit the CPU time
docker run --cpu-shares relative to other containersYou can limit relative, you can give this container half of the total CPU time, and other one the other half, so if one’s not busy, the other can use more CPU, but they’ll enforce it that they’ll have equal access.
You can also give them hard limits
docker run --cpu-quota to limit in generalYou can say this container only gets to use 10% of the CPU even if the other 90% is idle.
Most of the orchestration systems require you to state limits of a particular task or a container.
Exposing Ports
Docker offers a wide variety of options to connect containers together and connect containers to the internet.
For connecting them together, it offers private networks where you can put each container on a network and they can talk to each other, but still be isolated from the rest of the containers running on your computer.
For getting data into and out of the system as a whole, Docker offers the option of exposing a port or publishing a port. That makes the port accessible from outside the machine on which docker is being hosted.
docker run --rm -ti -p CONTAINER_PORT:OUTSIDE_HOST_MACHINE_PORT --name CONTAINER_NAMEIf we don’t mention the host machine port then docker will choose a random port. We can check the ports assigned of the container using
docker port CONTAINER_NAMEIf we want to mention the protocol such
tcporudpthen we can do it like thisdocker run --rm -ti -p CONTAINER_PORT:OUTSIDE_HOST_MACHINE_PORT/PROTOCOL CONTAINER_NAME
Container Networking
When we expose a container’s port in docker, it creates a path from essentially, the outside of that machine down through networking layers and into that container. That’s very well and other containers can connect to it by going out to the host, turning around, and coming back in along that path. It’s useful but there are more efficient ways to go about it.
Docker offers an extensive set of networking options to connect containers with each other.
To check existing networks, we see three networks by default
docker network ls
OUTPUT :
NETWORK ID NAME DRIVER SCOPE
3ce38069cd9c bridge bridge local
e08529dd4dd2 host host local
833eb8d13090 none null local
bridgeis used by the containers that don’t specify a preference to be put into any other network.hostis when you want a container to not have any network isolation at all. This does have some security concerns.noneis for a container when it should have no networking.
To create a network
docker network create learning
Names are very useful when using private networks in Docker, because different containers inside the network can refer to each other by those names, so it makes it very easy for them to find each other.
To define network while creating container use --net option
docker run --rm -ti --net NETWORK_NAME --name CONTAINER_NAME ubuntu bash
To connect a container to a network after creation
docker network connect NETWORK_NAME CONTAINER_NAME
Images
To list images
docker images
OUTPUT :
redis latest cc69ae189a1a 8 weeks ago 105MB
alpine latest e50c909a8df2 2 months ago 5.61MB
postgres latest 4ea2949e4cb8 2 months ago 314MB
ubuntu 16.04 8185511cd5ad 3 months ago 132MB
ubuntu latest f63181f19b2f 3 months ago 72.9MB
ubuntu 18.04 c090eaba6b94 3 months ago 63.3MB
mysql latest c8562eaf9d81 3 months ago 546MB
ubuntu 14.04 df043b4f0cf1 7 months ago 197MB
As these images share a lot of underlying data, you don’t sum up the size of these images to get the total space docker is using. Docker is much more space efficient than it would look like
To tag images :
docker committags images for youThis is an example of name structure for naming the images
registry.example.com:port/organization/image-name:version-tagWe can leave out the parts we don’t need.
Usually
Organization/image-nameis often enough
Getting images :
docker pull- Run automatically by
docker run - Useful for offline work
- Opposite :
docker push
Cleaning Images :
Images can accumulate quickly
docker rmi image-name:tagdocker rmi image-id
Volumes
Volumes are sort of like shared folders, they’re virtual discs that you can store data in and share them between the containers and between containers and the host, or both.
So there are two main varieties of volumes.
- Persistent : You can put data there and it will be available on the host, and when container goes away, the data will still be there.
- Ephemeral : These exist as long as container is using them, but when no container is using them, they evaporate. So they’re sort of ephemeral, they’ll stick around as long as they’re being used, but they’re not permanent.
These are not part of images, no part of volumes will be included when you download/upload an image. They’re for your local data, local to the host.
Sharing data with the host
Make a folder in your home directory named example and put some files in there. And run the given command
docker run --rm -ti -v ~/example:/shared-folder ubuntu:14.04 bash
When we’ll run the container the shared-folder in root directory will have those files and if we’ll create new files in shared-folder it’ll automatically reflect in example immediately and vice versa is also true. Both folders are in sync state and any change in one will be reflected in the other folder.
Sharing data between containers
First create a container and create a volume like this
docker run --rm -ti -v /shared-data --name rdb ubuntu:14.04 bash
Then create one more container and use that shared volume using --volumes-from param
docker run --rm -ti --volumes-from rdb --name rdb2 ubuntu:14.04 bash
Both the containers will have the directory named shared-data and any change in directory in one container will automatically be reflected in other container.
And as we exit all the containers, it’s gone.
Docker Files
Docker files are small programs designed to describe how to build a docker image.
You run these programs with
docker build -t name-of-result .
So each step produces a new image. It’s got a series of steps, start with one image, make a container out of it, run something in it, make a new image. The previous image is unchanged, it just starts from that, make a new one with some changes in it.
The state is not carried forward from line to line. If you start a program on one line, it only runs for the duration of that line.
So as a result if your build process is download a large file, do something with it, and delete it, if you do all that in one line, then resulting image will only have result of that.
If you download it in one line, it will get saved into an image. The next line will have that image saved there, and the space occupied by your big downloaded file will be carried all the way through and your docker file can get pretty big.
In Docker file, caching is done at each step. If we re run the file, it will only re run the steps changed and steps after that.
Processes you start on one line, will not be running on the next line. You run them, they run for the duration of that container, then that container gets shut down, saved into an image, and you have a fresh start on the next line.
Environment variables do persist across line if you use
ENVcommand to set them.Just remember that each line is its own call to
docker runand then its own call todocker commit
IMPORTANT LESSONS FROM EXPERIENCE
- Don’t let your containers fetch your dependencies when they start. If you’re using something like
Node.jsand you have your node starts up when the container starts it fetches it’s dependencies. Then, someday somebody’s gonna remove some library from node repos and suddenly everything stops working. Make your containers include dependencies inside them, saves a lot of pain. - Don’t leave important things in unnamed stopped containers.