Concurrency & Parallelism
Flynn’s Taxonomy
One of the most widely used systems for classifying multiprocessor architectures is Flynn’s Taxonomy, which distinguishes four classes of computer architecture based on two important factors
- Number of concurrent instructions or control streams
- Number of data streams

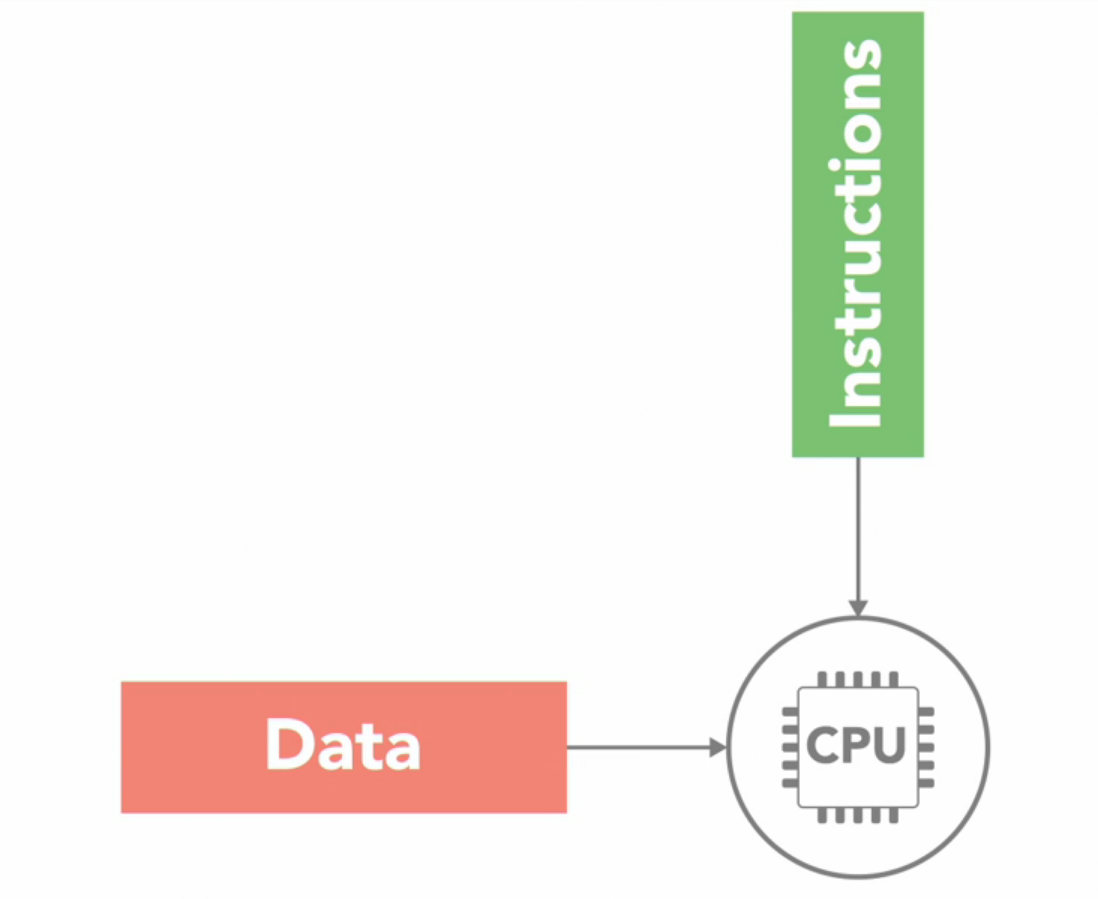
SISD (Single Instruction Single Data)
It’s very simple, there is just single instruction stream and single data stream on which those instructions will be executed.
In this there is just single CPU.
SIMD (Single Instruction Multiple Data)
In this there are multiple CPUs, they all execute the same instructions at the same given time but on different data and in sync with each other.
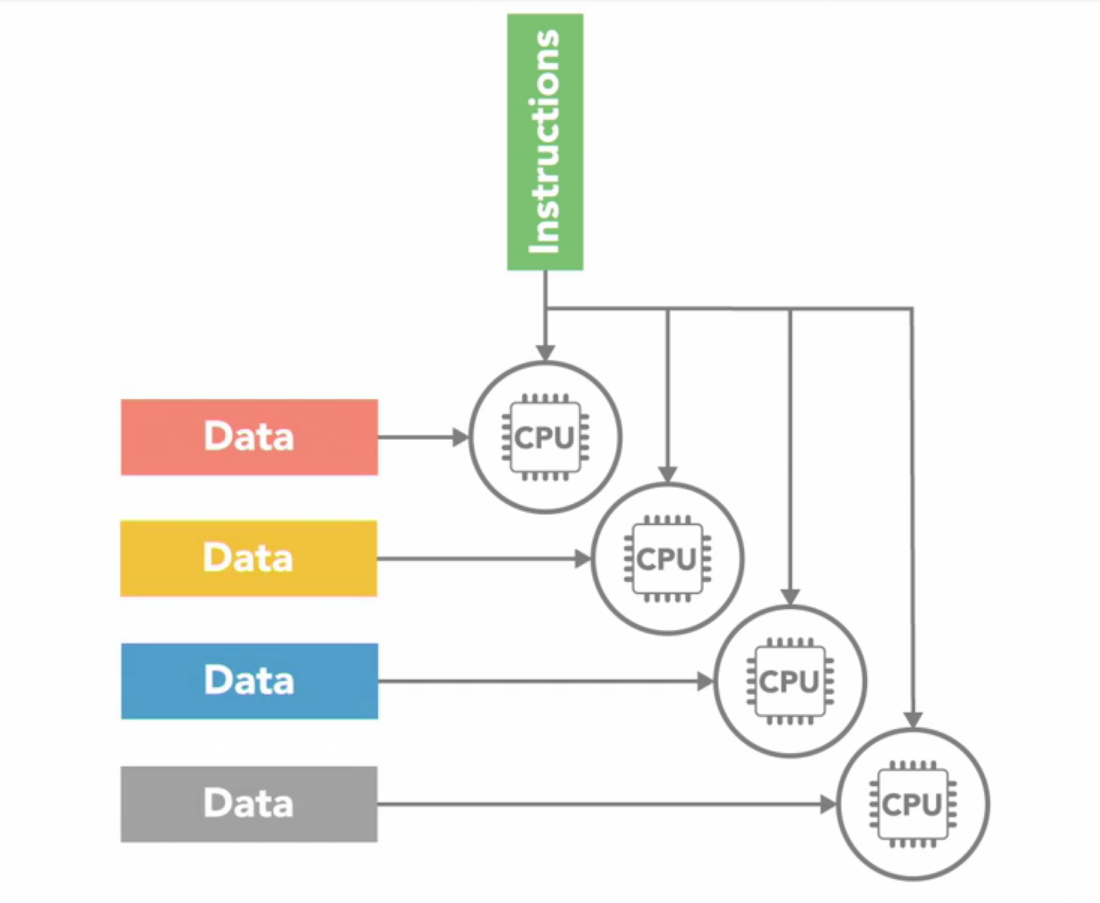
This type of SIMD architecture is useful for applications that perform the same handful of operations on a massive data element like image processing. Most modern computers use GPUs(Graphic Processing Unit), with SIMD instructions just to do that.
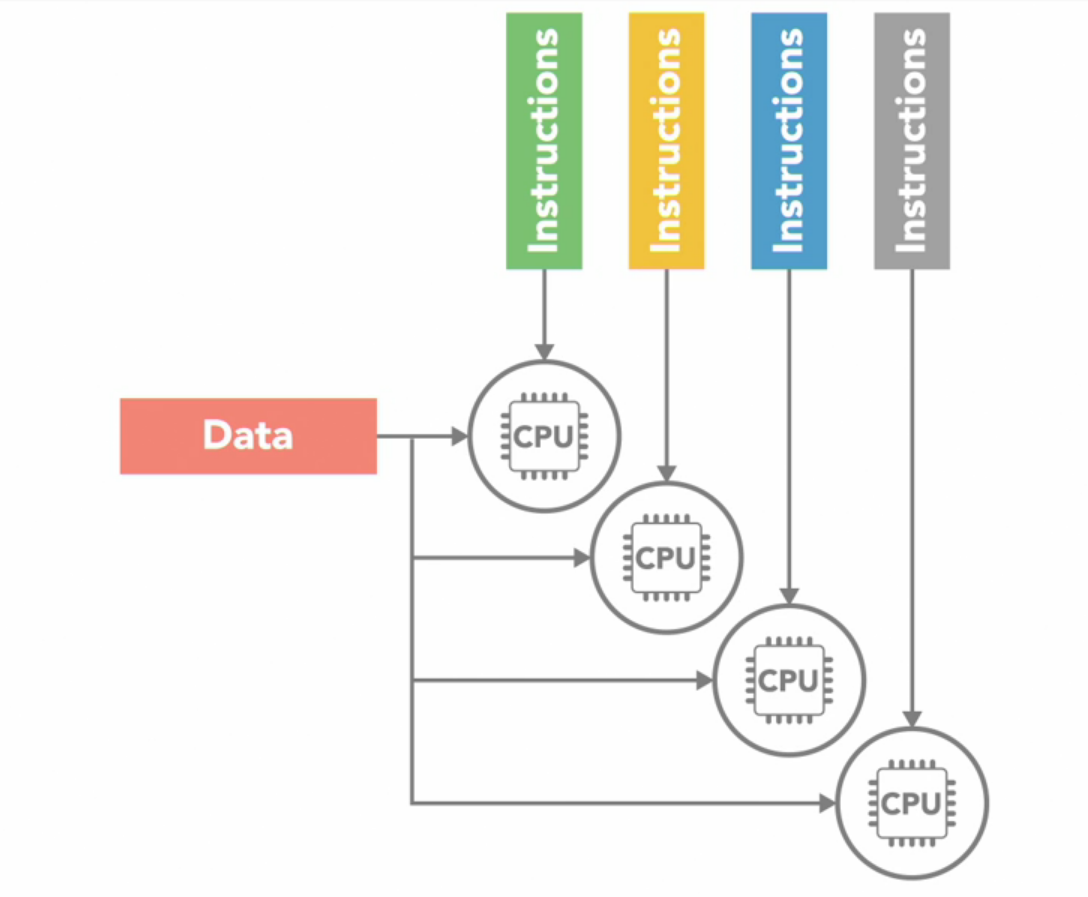
MISD (Multiple Instruction Single Data)
In this multiple instructions are executed on same set of data at one point of time. It’s like two people trying to cut and peel a carrot at a single point of time which frankly doesn’t make any practical sense.
MIMD(Multiple Instruction Multiple Data)
In this each processor is executing a different set of instruction at a time, and each of them can be processing on a different set of data.
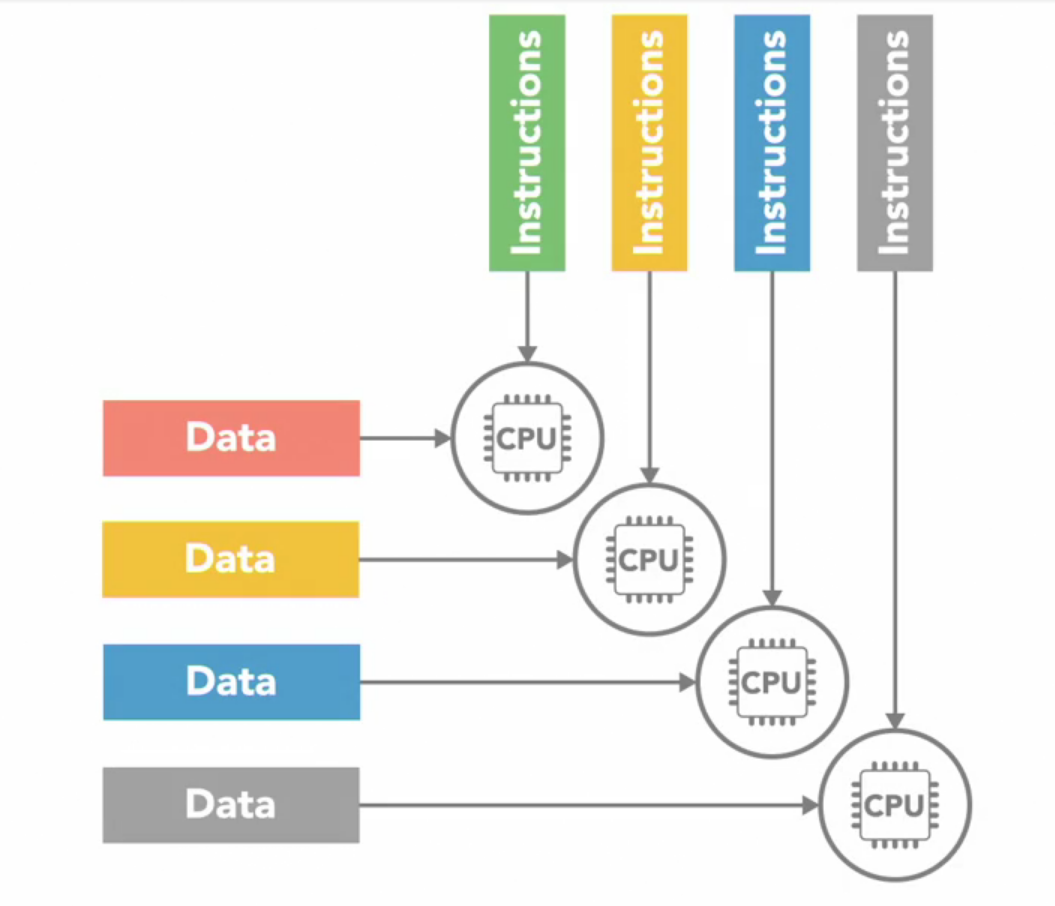
MIMD is the most common used architecture and we can find it in today’s multi-core PCs to super computers. Now this MIMD category is further divided into two categories
- Single Program, Multiple Data(SPMD)
- Multiple Program, Multiple Data(MPMD)
SPMD
In this multiple processing units are executing a same copy of program simultaneously, however they execute on different data. That might sound a lot like SIMD architecture but it’s different, because although each processor is executing the same program, they do not have to executing the same instruction at the same time. And usually there is conditional logic involved in program that execute certain parts of it based on data input. This is the most common style of a parallel program.
MPMD
In this processors can be executing a different independent programs at the same time on different data. Typically in this model one processing node is selected as the host, or manager which runs one program which sends data to other nodes running their own programs. Those other nodes do their work and return their result to the manager. MPMD is not as common but can be useful for applications which can be processed by functional decomposition.
Shared vs Distributed Memory
In addition to computer architecture, another import aspect to consider is memory. You could put a billion processors in a computer but if they cannot access memory fast enough to get instructions and data they need then you won’t gain anything from having all those processors.
Computer memory usually operates at a much slower speed than processors do, and when processor is reading or writing to memory that often prevents any other processors from accessing the same memory element.
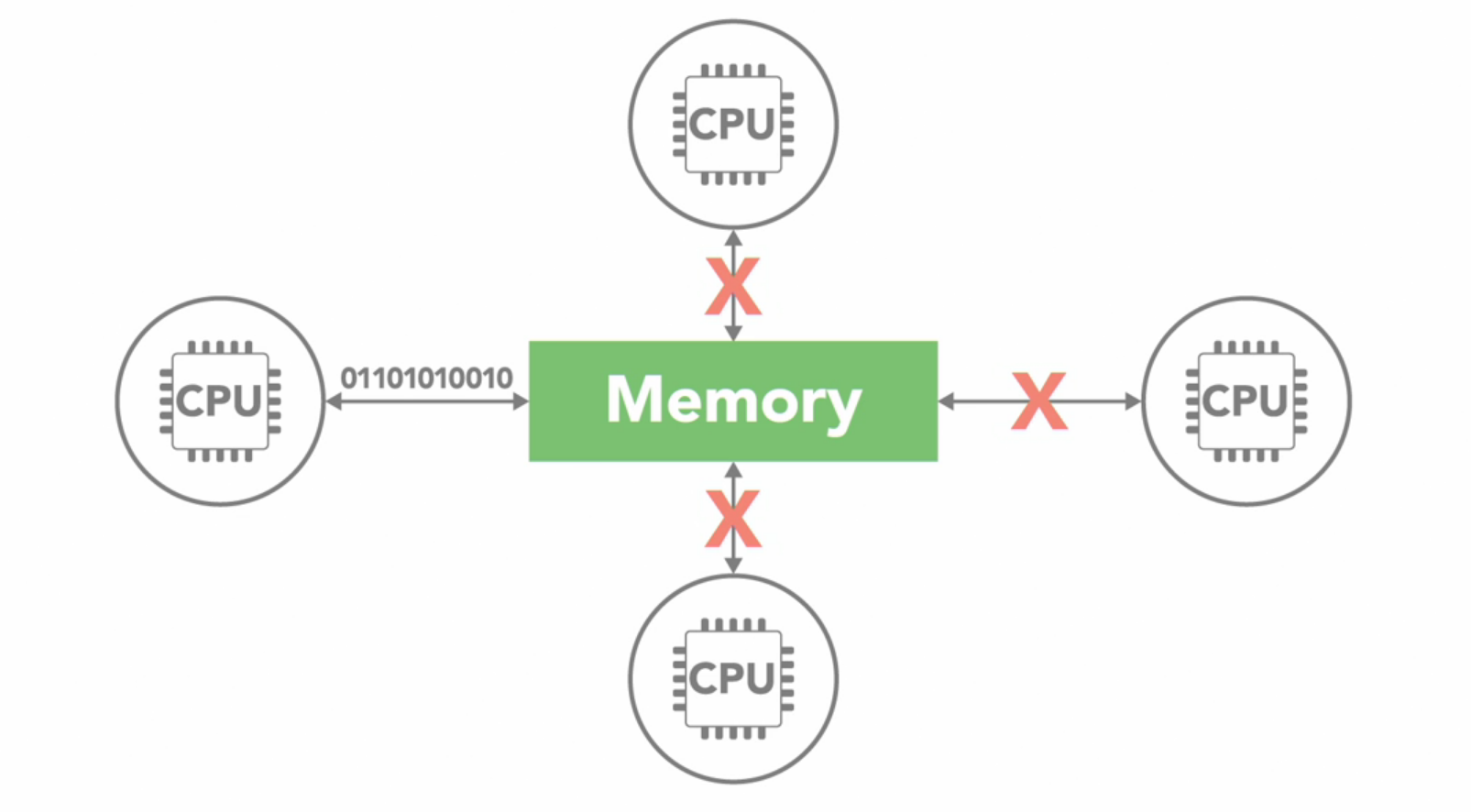
There are two main memory architectures that exist for parallel computing
- Shared Memory
- Distributed Memory
Shared Memory
In shared memory system, all processors have access to same memory as part of global address space.
Although each process operates independently, if one processor changes a memory location all the other processors will see that change.
Now the term shared memory doesn’t mean all of this data exists on same physical device, it could be spread across a cluster of systems. The key is that our processors see everything that happens in the shared memory space.
Shared memory is often classified into two categories which are based on how processors are connected to memory and how quickly they can access it :
- Uniform Memory Access(UMA)
- Non Uniform Memory Access(NUMA)
Uniform Memory Access :
In UMA architecture all processors have access to memory meaning they can access memory equally fast.
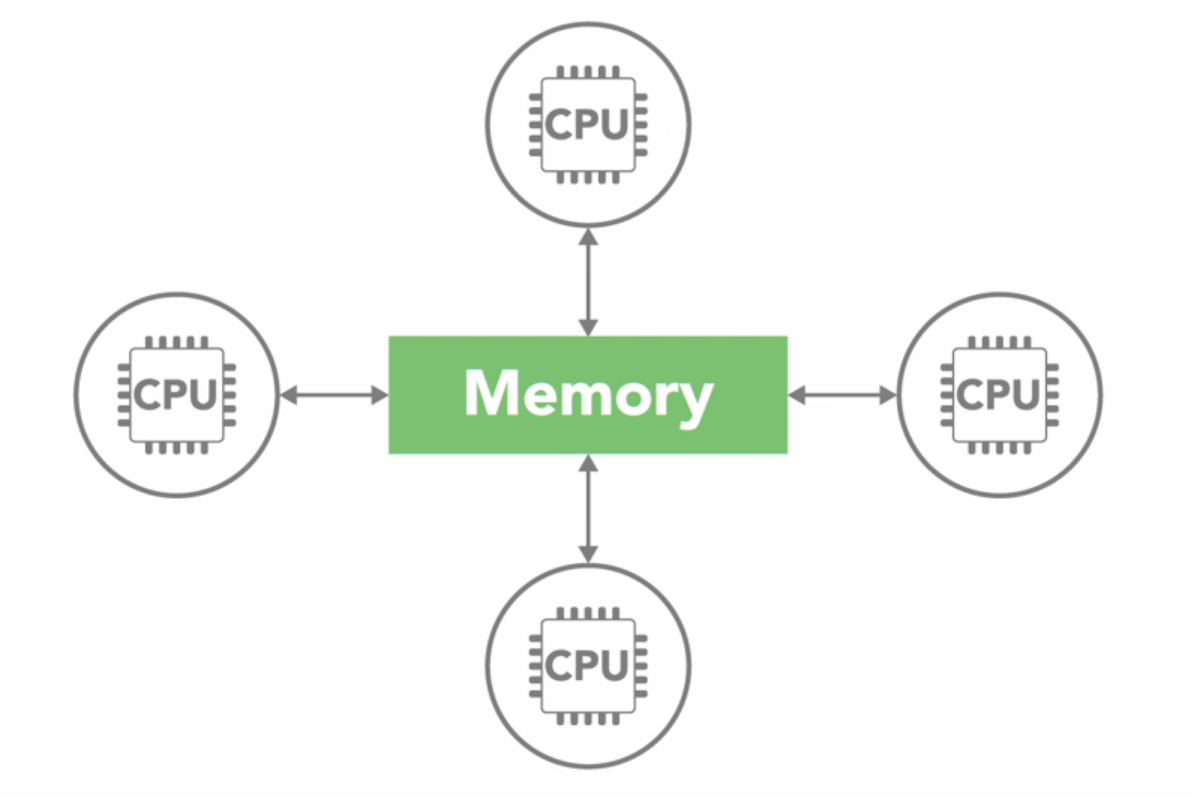
There are several types of UMA architectures, but most common is symmetric multiprocessing system or SMP.
An SMP system has two or more identical processors which are connected to single shared memory often through a system bus.
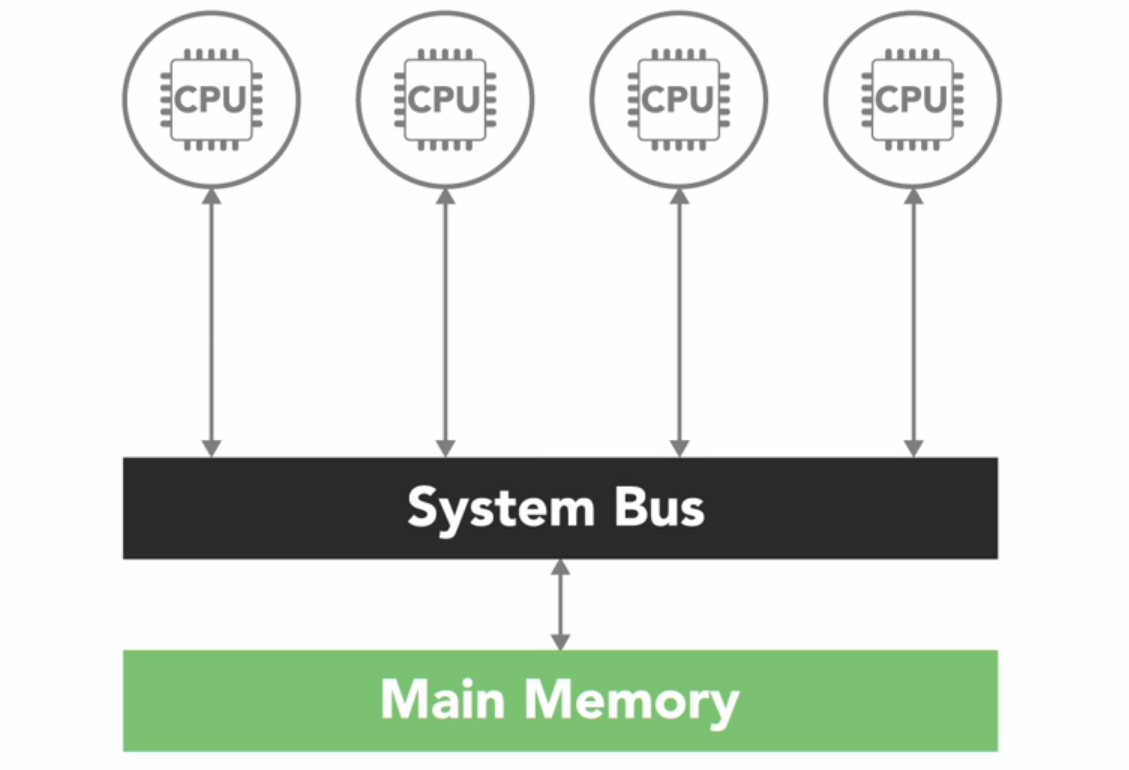
In case of modern multi-core processors, which you find in everything from desktop computers to cell phones, each of the processing cores is treated as separate processor.
For this series we’ll focus on SMP architecture.
In most modern processors, each core has its own cache which is a small very fast piece of memory that only it can see. And processor use it to store data that its frequently working with.
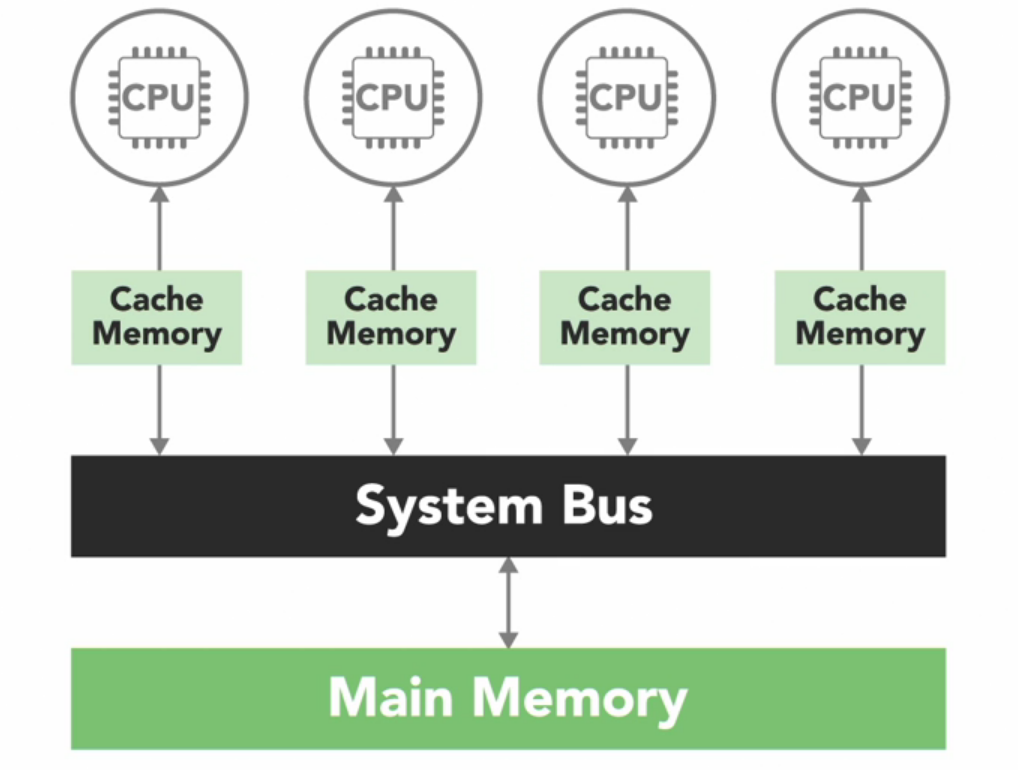
However cache introduces the challenge that if one processor copies a value from the shared main memory, and makes changes in the local cache, then that change needs to be updated in the shared memory before another processor reads the old value which is no longer current. This issue is called cache coherency is handled by the hardware in multi-core processors so we will not go into that detail.
Non Uniform Memory Access :
This type of system is usually made by connecting multiple SMP systems together. The access is non uniform because some processors will have quicker access to certain parts of memory than others. It takes longer to access things over the bus. But overall, every processor can access every part of the memory.
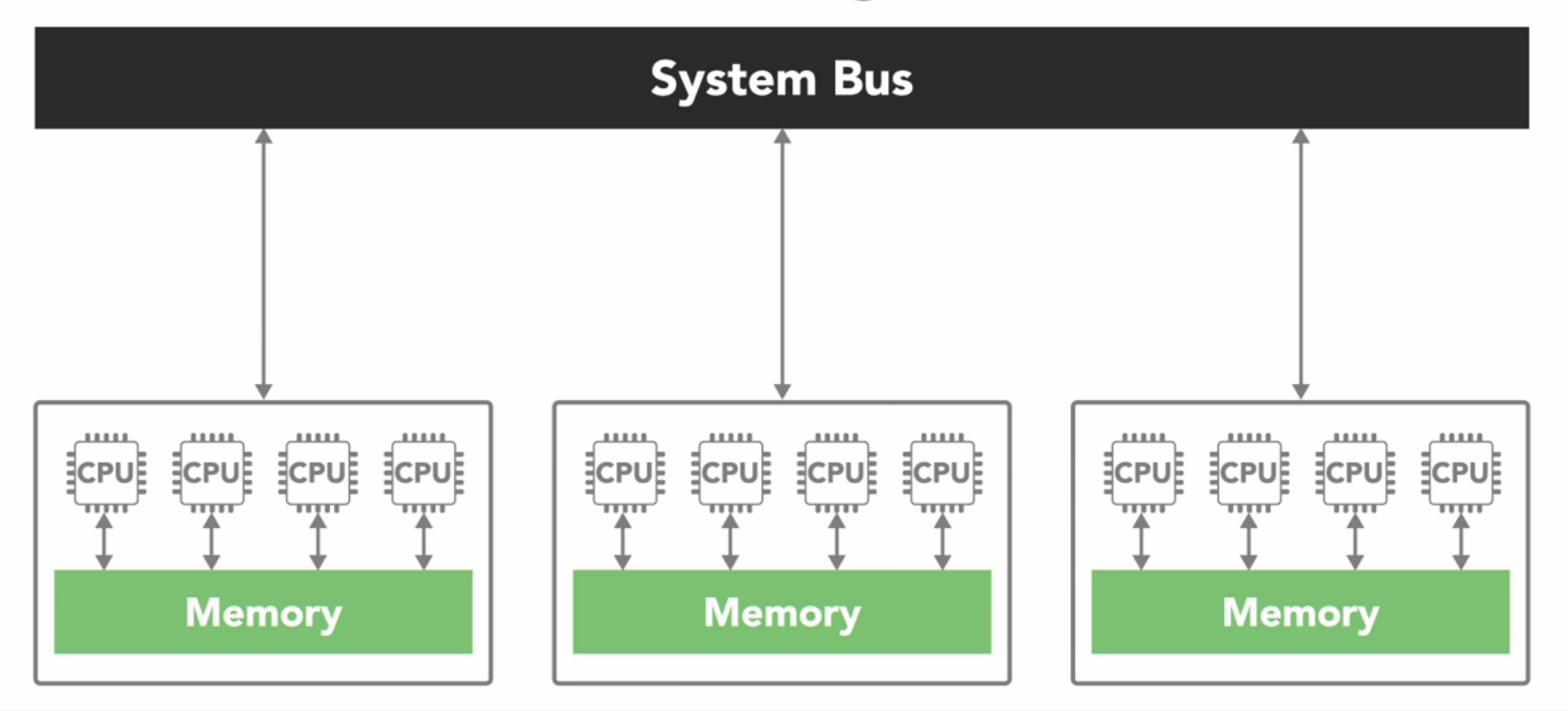
These shared memory architectures have advantage of being easier for programming, in regards to memory because it’s easy to share data between different parts of a parallel program. The downside is that they don’t always scale well. Adding more processors to shared memory will increase traffic on shared memory bus. And if you factor maintaining the cache coherency it becomes a lot of communication that needs to happen between a lot of parts. In addition to that, shared memory puts responsibility on the programmer to synchronise memory access to ensure correct behaviour.
Distributed Memory Architecture
In a distributed memory system, each processor has its own address space so the concept of global address space doesn’t exist. All of the processors are connected to some sort of network.
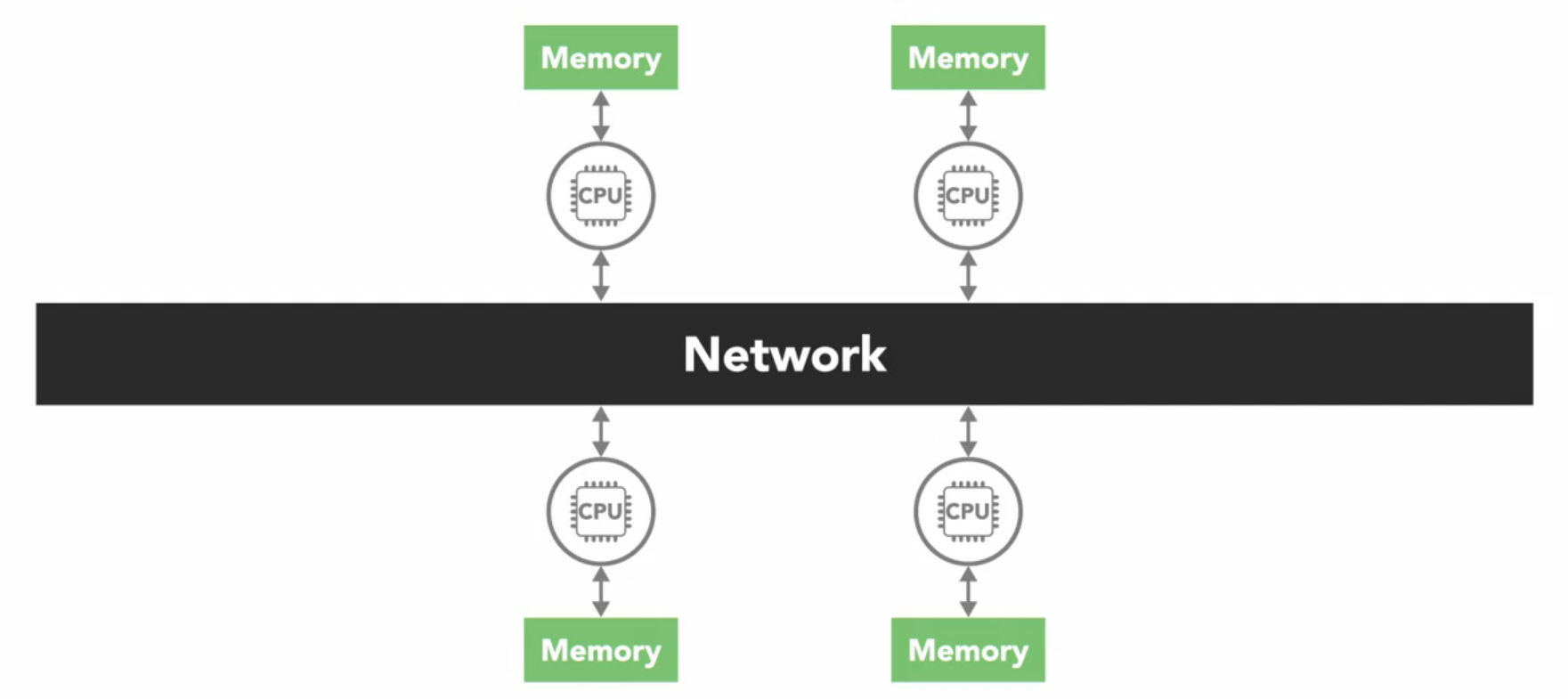
All of the processors are connected through some sort of network which can be as simple as ethernet. Each processor operates independently, and if it makes changes to its local memory that change is not automatically reflected in the memory of other processors. Its up to programmer to explicitly define how and when data is communicated between different nodes of distributed system, and that’s often a disadvantage.
The advantage of a distributed memory architecture is that its scalable. When you add more processors to the system, you get more memory too. This structure makes it cost effective to use commodity, off-shelf computers, and networking equipment to build large scale distributed memory systems.
Most super computers use some form of distributed memory architecture, or a hybrid of distributed and shared memory.